In the major part of virtual data center project, the storage array/system represents the critical design choice that determines to success or the fail of the entire infrastructure. In most cases, the same single huge and performing storage array used to serve multiple environments and several data ( sometimes without taking care of cost and impacts for a single workload ) could be the first cause of unjustified increase for the investments to start or keep environment healthy.
In fact, in a lot of scenarios the highest amount of data is consumed by processes that are not directly involved with the production pipeline, like test and dev environments, file server, backups and big data/analytics.
Cohesity, a company born in 2013, claims to be the definitive solution for these data providing a secondary storage: a hyper-converged storage system for backup, DR and more, with an interesting way to govern the data. The success of this technology resides in its architecture and, more specially, in its SpanFS: a filesystem with an interesting clustering system and a huge scalability.
During StorageFieldDay 15 we had the pleasure to visit their offices in San Jose and a great conversation with the staff in their meeting room.
The data center iceberg!
Today, a lot of enterprise data are spread across multiple data center or in hybrid environments using several cloud services based on Infrastructure, Platform and Software As a Service. The first drivers in cloud adoption are the simplification and the lowest TCO for all processes that could run “outside the company”. The increased deployment speed and the affordable cost model (effectively calculated to the used workload) are disciplining the data governance: simply, if I pay for the amount of data/services, I’ll put more attention for what really deserve a cloud resource.
But the on-premise environments tell another story: seems that have a prepared quantity of storage/computing and networking can justify the uncontrolled data explosions and/or the not well-defined models of governance. The simple storage separation (logical/physical) is not enough: while new technologies imposes to really take care about data purpose and involvement in the company processes, the “mess” made of “forgotten workloads” and “unmanaged data” still reigns supreme.
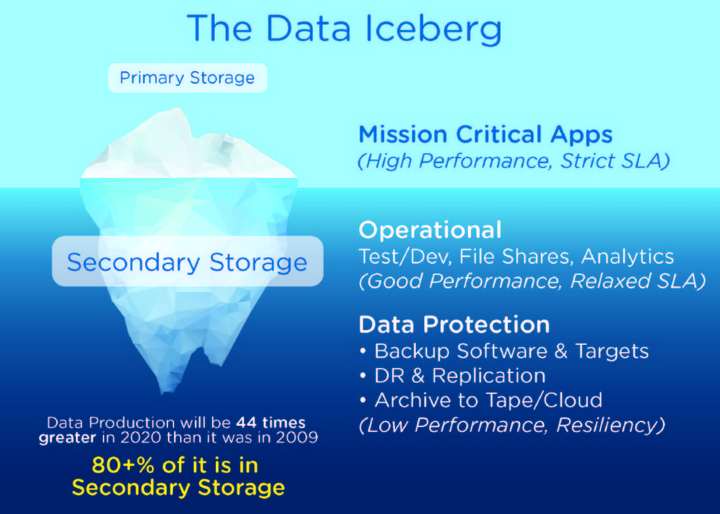
In the same time operational and backup data are often placed “everywhere” in the environment, causing an ungovernable situation of what is really mission critical and what is important for their retention. What’s the cost to maintain these secondary data?
Cohesity is focusing on store and govern these data: using and hyper-converged architecture, this intersting solution gives:
- a scale out infrastructure to handle and manage the secondary data
- a secure distributed filesystem able to extend the on-premise capabilities using public cloud environments (like Azure and AWS) and more…
- a system that guarantee protection and reduced time to recover for data and services
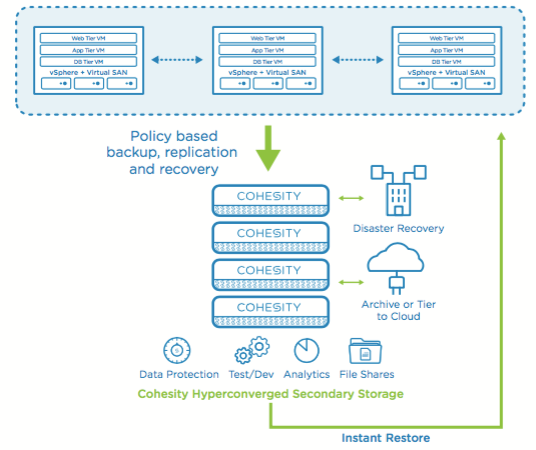
An hybrid cloud filesystem for secondary data
SpanFS is the core of Cohesity architecture, responsible for the access and data/metadata life cycle across on-premise and cloud system: a true and unlimited enterprise capable storage, able to expose NFS, SMB and S3 interface and global deduplication using inexpensive hardware system.
What really make the difference from another “simple” filesystem is the ability to global index the files included in the backuped VMs and use a search engine and analytics workbench.
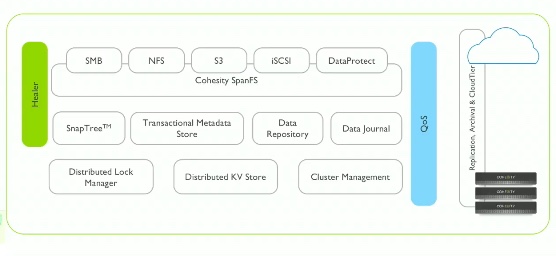
The data handling technology is sustained by metadata store and I/O Engine which scales linearly in terms of capacity and overall performances. Metadata are shared across every nodes and distributed lock manager guarantee its consistency, arbitrating access across the cluster.
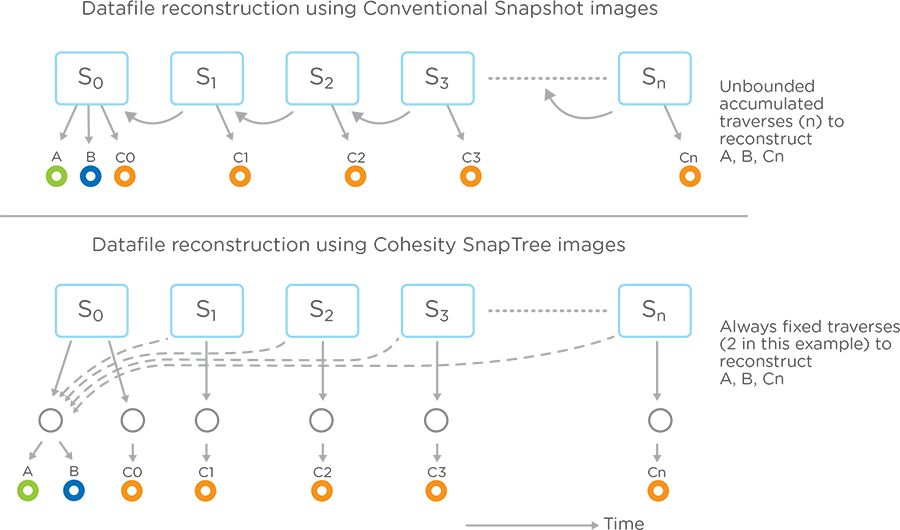
SnapTree, build on top of the distributed KV store, give the ability to instant-clone every files in this distributed filesystem so it is possible to create a transaction mechanism.
Another key component is the distributed data journal, which provide a low latency during every write across the cluster. Healer and QoS are responsible for keeping filesystem healthy, showing by map-reduce, a global view and prioritization of the I/O depending on data purpose.
[vsw id=”UDB2IZ0d1CY” source=”youtube” width=”425″ height=”344″ autoplay=”no”]
Wrap up
The data protection is still a challenge during backup design: near the choice of the backup solution, the place to store backup data could be difficult to justify during cost calculation. One of the popular mistake is deliver a simple and low cost cost NAS as backup and long term data repository, without thinking how critical they are during the recovery phase. Cohesity is a very good answer for this problem, providing a smart and secure place to store backup and secondary data. In the same time, the near 0 recovery time and the integration with AWS and Azure are valued plus which bring the opportunity to designing a recovery site or building a secondary data scale-out system with an affordable cost.
Check also Cohesity at Storage Field Day 15 here:
[vsw id=”_664AuihMlE” source=”youtube” width=”425″ height=”344″ autoplay=”no”]
Disclaimer: I have been invited to Storage Field Day 15 by Gestalt IT who paid for travel, hotel, meals and transportation. I did not receive any compensation for this event and None obligate me to write any content for this blog or other publications. The contents of these blog posts represent my personal opinions about technologies presented during this event.
[…] Storage Field Day 15: Cohesity the solution for secondary data […]
[…] Storage Field Day 15: Cohesity the solution for secondary data […]