I already introduced how to “dress” a PowerCLI script, wrapping its execution in a web service built with very low effort with Skaffolder. In the previous post, we left the “code” with a simple console.log as proof of the script execution.
Now it’s time to go further and handle the results coming from PowerCLI script.
Defining the pattern
Data coming from the executed script are simply text strings. If you plan the use them as “objects” for further operations, the best way is to convert them in JSON or XML and transform in the object using a parser. But not all coming data are really useful: they need a format and a pattern which correctly identify the incoming object’s data, like VM, vSwitch, Datacenter usage,…
In the Skaffolder object model, a field called ResultType will carry the information using a JSON that describes the result type and the value. If you get a single value from the script a simple insert into Result table will be performed once data are gathered using the function
|
1 |
bat.stdout.on('data'... |
and object pattern in ResultType attribute could be:
|
1 2 3 4 |
{ "type":"single", "name":"result" } |
In case of multiple results like an array composed by virtual machines (the case of “test.ps1” script) you can define the following pattern:
|
1 |
{ "type":"list", "name":"vm" } |
Note: if you’re using Swagger doc UI don’t forget to escape the value “ with \”
Storing data
NodeJS with child process library handles the incoming stream asynchronously and multiple times regardless the coherence of the data itself.
For this reason, after every database operation you must place the next instructions inside a callback function like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
// Purge old data db_PowerCLILaunch_db.Result.remove({ScriptExecution:oExecutionData._id},function(err){ if (err){ console.log(err); } oExecutionData.HasResults = ""; db_PowerCLILaunch_db.ScriptExecution.findByIdAndUpdate(oExecutionData._id, oExecutionData, {'new': true}, function(err, obj){ if (err){ console.log(err); } }); }); |
As I said before, the function bat.stdout.on(“data” it’s invoked every time a stream of data arrives from the script and it could happen that a complete set of results arrives in more than one stream.
For this reason is important to gather all result as a single string before proceeding with parsing operation. In few words only bat.on(“exit” function must complete the data insertion in the database.
One of the key features in NodeJS is the persistence of some variables during the entire asynchronous process. If you declare variable before starting the process, the control is correctly released but the process is still running and all declared variables are still valid during on.data, on.err and on.exit:
Finally, data are stored in “Result” table giving the Execution.id as the foreign key. Here the code in launch script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
bat.stdout.on('data', (data) => { console.log("incoming data " + iProcessRun); //console.log(data.toString()); sData += data.toString(); oExecutionData.HasResults = "Data"; db_PowerCLILaunch_db.ScriptExecution.findByIdAndUpdate(oExecutionData._id, oExecutionData, {'new': true}, function(err, obj){ if (err){ console.log(err); } }); }); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
bat.stderr.on('data', (data) => { console.log("Error" + iProcessRun); // Write error into results oExecutionData.HasResults = "Error"; var oResultErr = { Name:'error', Value: data.toString(), //EXTERNAL RELATIONS ScriptExecution: oExecutionData._id }; var oErr = db_PowerCLILaunch_db.Result(oResultErr); oErr.save(function(err){ if (err){ console.log(err); } db_PowerCLILaunch_db.ScriptExecution.findByIdAndUpdate(oExecutionData._id, oExecutionData, {'new': true}, function(err, obj){ if (err){ console.log(err); } }); }); }); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
bat.on('exit', (code) => { console.log("End of script" + iProcessRun); //console.log (sData); oExecutionData.State = "End-"+iProcessRun; db_PowerCLILaunch_db.ScriptExecution.findByIdAndUpdate(oExecutionData._id, oExecutionData, {'new': true}, function(err, obj){ if (err){ console.log(err); } if (sData != ""){ // Finally store data var oData = JSON.parse(sData); var oResData = JSON.parse(oExecutionData.ResultType); if (oResData.type == "list"){ for (var i=0; i < oData.length; i++){ oResult = { Name:oResData.name, Value: JSON.stringify(oData[i]), //EXTERNAL RELATIONS ScriptExecution: oExecutionData._id }; oRes = db_PowerCLILaunch_db.Result(oResult); oRes.save(function(err){ if (err){ console.log(err); } }); } }else if (oResData.type == "single"){ oResult = { Name:oResData.name, Value: JSON.stringify(oData), //EXTERNAL RELATIONS ScriptExecution: oExecutionData._id }; oRes = db_PowerCLILaunch_db.Result(oResult); oRes.save(function(err){ if (err){ console.log(err); } }); } } }); }); |
The code can be optimized with a function (or better a static object) that can handle this function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
var DbUtils = { insertResultsFromScript: function(sId, sName, sValue, oCallback){ oResult = { Name:sName, Value:sValue, ScriptExecution: sId }; var oRes = db_PowerCLILaunch_db.Result(oResult); oRes.save(function(err){ if (err){ console.log(err); } oCallback(); }); } } |
And the implementation should be
|
1 2 3 |
DbUtils.insertResultsFromScript(oExecutionData._id, oResData.name, JSON.stringify(oData[i]),function(){ // Done }); |
Retrieve the results
Now data and errors should be correctly stored in a table using a JSON string.
Skaffolder automatically generates a GET method to retrieve all results. It’s time to put the hands on Skaffolder again to refine the data retrieving, using Model View add a SEARCH API called Findby in “Result” table:
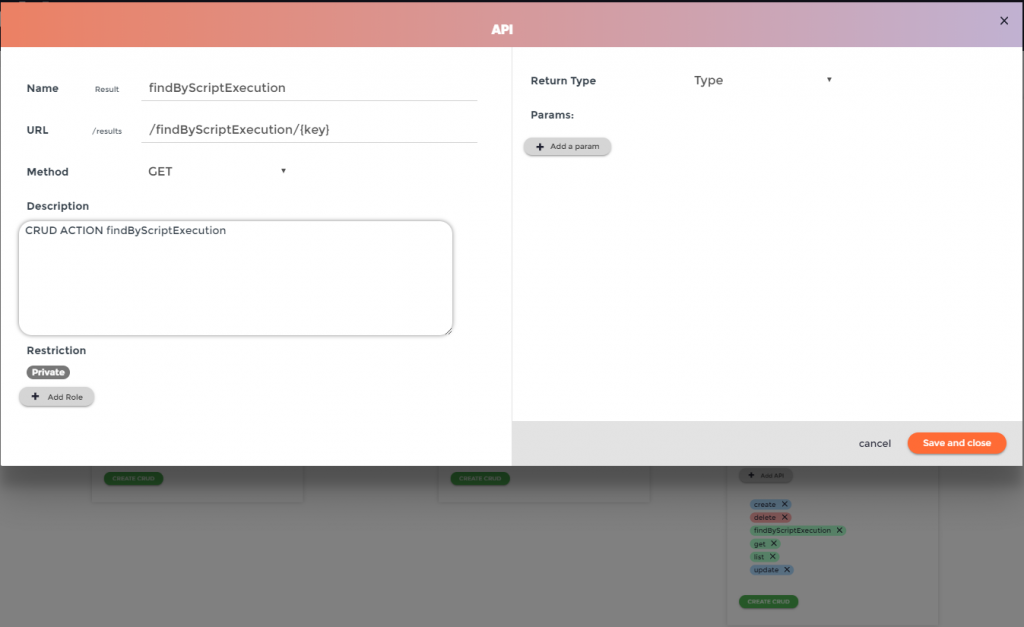
Don’t forget to add a param named “key” with “String” as type.
Then generate the code again using Skaffolder CLI.
Note: Following the README indications about where to put your custom code, you’ll never encounter losses of code. Anyway I suggest to make a backup copy of “what you have done” after the previous generation in order to avoid unwanted code modification.
Skaffolder is keeping track on modified file before regenerating code. For this reason the suggested way to work is:
- update/modify files in “custom” directory
- modify template directory if you want to generate code with custom modifications such as url declaration in swagger.yaml file.
- in case of modified swagger.yaml just move it out of project directory in order to generate the correct set of method you’ve created in model view.
And without writing code, you’ll have a fully functional method to retrieve an only specific set of records dependent from the single script execution.
Few tips again…
Handling results such as data or error are not finished by a simple insert into the database of the record set. In the real world, data could are modified during infrastructure life-cycle. At first look, a simple delete and store procedure could be enough to show a simple results.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
var iProcessRun = (new Date).getTime(); oExecutionData.State = "Running-"+iProcessRun; // Purge old data db_PowerCLILaunch_db.Result.remove({ScriptExecution:oExecutionData._id},function(err){ if (err){ console.log(err); } oExecutionData.HasResults = ""; db_PowerCLILaunch_db.ScriptExecution.findByIdAndUpdate(oExecutionData._id, oExecutionData, {'new': true}, function(err, obj){ if (err){ console.log(err); } }); }); |
But if you plan to use these data for further operations is possible to use three extra fields in results that could keep a kind of historical change:
- ExecTime: last insert/update
- UUID: an extra index from infrastructure (such as a combination of infrastructure and VM IDs)
- State: present or deleted depending on the value returned from the script