For the first time ever in a Tech Field Day, Weka.io presented Matrix, an hyper converged filesystem with different rules and an interesting application in on-premises infrastructure and in cloud environments based on AWS. In fact this young software company situated in San Jose (CA) has an interesting scalable parallel filesystem that best fits on AI processes, low-latency environments and all applications which requires speed and protection as well.
At Storage Field Day, Liran Zvibel, Barbara Murphy and Shimon Ben David gave us a deep technical introduction with a live demo. Let’s see in-depth
A software company… with an interesting technology
One of the important message that came out from the discussion is that Weak.io is selling software: the company’s strategy is to provide a component that could gain their presence in the storage eco-system using hardware commodity.
This is the reason why Weka.io partnership is very consistent in cloud and hardware ecosystems: HPE, DELL, CISCO, AWS, Google,… (check here the full list).
Giving a look at performance/capacity relation, we must consider traditional storage arrays divided in two groups:
- performance and low capacity
- capacity and low performances
But where is and how much cost a huge capable storage that keeps high performances at every scale? The answer stay in the software: Matrix filesystem is built to give a scale-out and clustered system based on hardware commodity, with the same performance of a powerful scale out storage system.
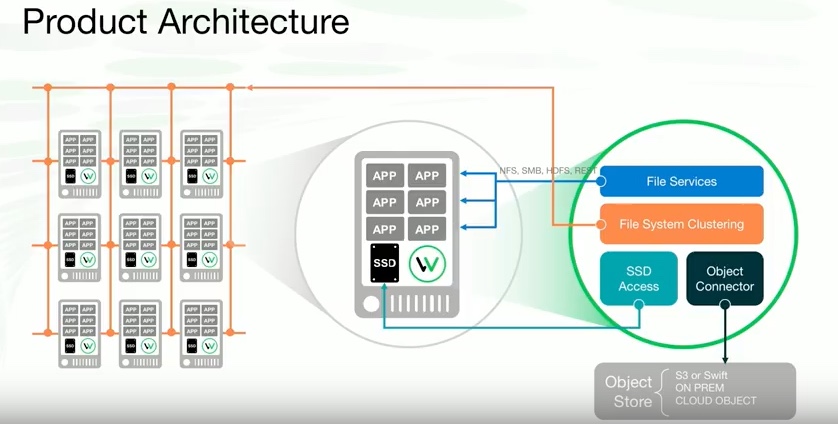
Under the hood of Weka.io, there are some key elements which are contributing to realize a real software defined scale out system, able to handle thousand of computing nodes without compromise the overall performances:
- A file service upon a clustered filesystem
- A SSD Access that handles the “local” SSD or NVMe drive running on infiniband or ethernet.
- An object connector, able to scale and handle the concurrency of this filesystem locally or in cloud using S3 or swift protocols.
In a linux system, application make sys calls to VFS driver. At user-space the sys call is handled by a front-end component to communicate to S3, NFS, SMB… In the same time the front-end components communicate through the network to backend to handle the protection, metadata and “tiering”. The backend is not a single element, but is composed by small pieces distributed across many servers, and is possible to assign resources (cores, memory and SSD/NVMe devices).
The data locality in HCI
In Hyperconverged solutions, one of the focus of many discussion is about storage and in particular in the mechanisms to provide performance, resiliency and scalability. Data locality is the way for a single host to access to the owned data. In HCI, the mechanism to access in Read and Write a single owned data, is what differentiate the several solution.
If fact without data locality a single write runs at least by two hosts. With data locality only one write effectively runs across a different host crossing the network: the others will take places inside the owned host. Reads could give more benefits running in data locality environment, because read I/O will be only in the owned host and never runs across the network.
There’s an interesting article that IMHO best shows this concept: https://www.virtualizationpractice.com/matters-data-locality-hyperconverged-38900/
Weka.io is believing on the put every IO on the network to ensure protection at every scale… in few words: data locality is irrelevant because modern networks are faster than SSD.
For further explains about Weka.io mechanism, just check the Liran’s presentation during Storage Field Day:
[vsw id=”Cn7VGbiO9Us” source=”youtube” width=”425″ height=”344″ autoplay=”no”]
and the demo by Shimon Ben David:
[vsw id=”QMdEo8-GS8E” source=”youtube” width=”425″ height=”344″ autoplay=”no”]
Wrap up…
Weka.io Matrix is an interesting project that could fit in many HCI use cases like containers, virtual infrastructure, big-data and AI.
Data distribution, security features (like encryption), tiering provided by different media and snapshots across multiple environments are placing this product as an interesting infrastructure element to distribute “objects” across on-premise environments and AWS, allowing elasticity in delivering workload across hybrid environments.
If you want to get started with weka.io and evaluate feature and performances check the official “get started” page: https://www.weka.io/get-started/.
Disclaimer: I have been invited to Storage Field Day 15 by Gestalt IT who paid for travel, hotel, meals and transportation. I did not receive any compensation for this event and None obligate me to write any content for this blog or other publications. The contents of these blog posts represent my personal opinions about technologies presented during this event.