Today, during architecture design, the choices from old, converged and the hyper-converged infrastructures are strictly bound to capacity metrics and performance metrics which a required by the application. Analyzing the workload, the relation between CPU/MEM with Storage and Networking is the critical point that guides the decisions about the hardware acquisition.
But a group of experts, coming from different experiences about virtualization and storage, reinvented the computing and storage convergence rules, building another way of delivering Tier-1 and Secondary data in a single and scalable solution. This is Datrium.
At Storage Field Day 15 we had the pleasure to meet: Sazzala Reddy (CTO and Co-Founder), Rex Walters (VP), Tushar Agrawal (Director of Product Management) and John Cho (MTS and Cloud Architect).
Let’s see in depth!
The architecture and the I/O mechanism
Hyper-convergence is now mostly used to well deliver Tier-1 application, where the entire cluster capacity is brought with the least minimum latency and the max available IOPS (more than classical shared storage). But the reality is that it’s hard to substitute the entire infrastructure with a full set of hyper-converged systems.
When you handle huge capacities with non-critical workloads, the traditional shared storage with diskless servers are still the preferred choice… or better are still a good and well-known solution.
Datrium claims to redefine the converged rules, building an affordable high scalable system composed by stateless Compute Node, and stateful Data nodes. This separation is something different from traditional HCI system and a traditional architecture that may comprise a converged system.
This new way to deliver storage and computer architecture is named open converged and believes in the power of building an entire data center with discrete elements, which can be handled by a single interface eliminating management complexities and guarantee high capacities and performances.
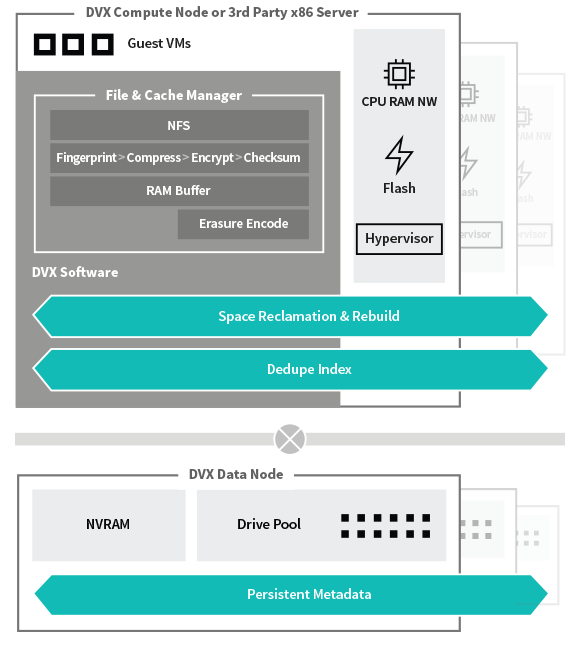
The core of the storage mechanism is inside the software component which is delivered in the hypervisor level which is directly involved in the protocol, cache, erasure code, deduplication, space reclamation and synchronization with data nodes.
Here the video of full explanation which is available in the official site too ( https://www.datrium.com/products/products-architecture/ ):
Focusing on storage mechanism every incoming write receive the acknowledge directly in the data node and pass through this pipeline:
- Dedupe
- In line compressed
- and stored in LFS container which is responsible to acknowledge the write to compute node
- then, the system proceeds with the split of the entire container 8MB in chunks applying the erasure coding to ensure an efficient grade of protection.
- Chunks are distributed across multiple disks
DVX data nodes use Log based filesystem which gains the following benefits: High performance, Data integrity, Cost Efficiency (by the use of commodity HDD and SSD applying an inline erasure coding), Dedupe Index and also is designed for the cloud.
Here some technical details about AlwaysON Erasure Coding and here more on Datrium architecture technologies
Performances and solution
During the conversation, an interesting aspect came out in the performance topic: Datrium has an “insane” ability to scale keeping performance at the highest available level. This was demonstrated with a true performance test executed in partnership with DELL. This recognizes in Datrium the largest HCI-like system ever measured!
Another important benchmark test was conducted in collaboration with IOmark.org, that audited and validated Datrium with a workload of 8000 VM running on 60 servers an 10 data nodes (12 x 1.94 TB SATA SSDs). And the results are really impressive: 10x faster than HCI. Check here the full report.
Global deduplication aware enable to distribute the workloads across multiple sites and in public cloud. Thanks to faster movement of data and a verification method similar to blockchain architecture, is possible to distribute and govern all the workloads in the same interface.
The open convergence with Datrium is not limited to Tier-1 Application, but there are some interesting solutions which cover several scenarios like Scale-out backup, secondary data management, Data Protection, and Disaster Recovery.
Additionally, Datrium is landed on the cloud! In order to stay in the actual trend of hybrid cloud infrastructures, there is a Datrium version which can run on Amazon AWS. This solution is the must you have to consolidate backup or use AWS as a second or third recovery site in a disaster recovery. Just create an AWS Account, put AWS key in on-premise infrastructure and set the protection policy. In AWS Datrium will deploy resources and pair with on-premise DVX.
Wrap up
Datrium is definitely rewriting the converged and the hyper-converged rules placing its product between the efficiency and the performance of the HCI cluster and the huge capacities which is still a requirement for new old and new applications. Anyway the architecture looks very adaptive and I hope to test or see this solution in action soon.
[…] Storage Field Day 15: The open convergence by Datrium […]
[…] https://blog.linoproject.net/storage-field-day-15-the-open-convergence-by-datrium/ […]