Today, the storage solutions are moving from “block” perspective, to data perspective: near the ability to consume disk space with the right level of availability and performance, the need for the new applications to transform huge amount of data, is the new must to have, near the freedom to move data across cloud systems.
In this scenario, the exclusive use of the big cloud provider, like AWS, could not be the solution for all use cases: more and more developers, driven by customer requests, are looking for a solution that simplify development and be ready for hybrid deployment. Another fact is the S3 protocol adoption, that is going adopted as an interesting solution for object storage integration in cloud native development.
In this way Scality (http://www.scality.com), a software company located at San Francisco (in a palace with a beautiful view of the bay), has build an interesting software defined solution able to bring x86 servers and build a multipurpose storage environment. The feature that deserve more attention for this scale-out filesystem, is the ability to access, move data across multiple cloud systems. Let’s see in-depth.
The architecture
Like said before, the Scality’s core element is the software that brings a “ring” of x86 server and realize a complete software defined storage solution with high capable filesystem able to expose files or objects.
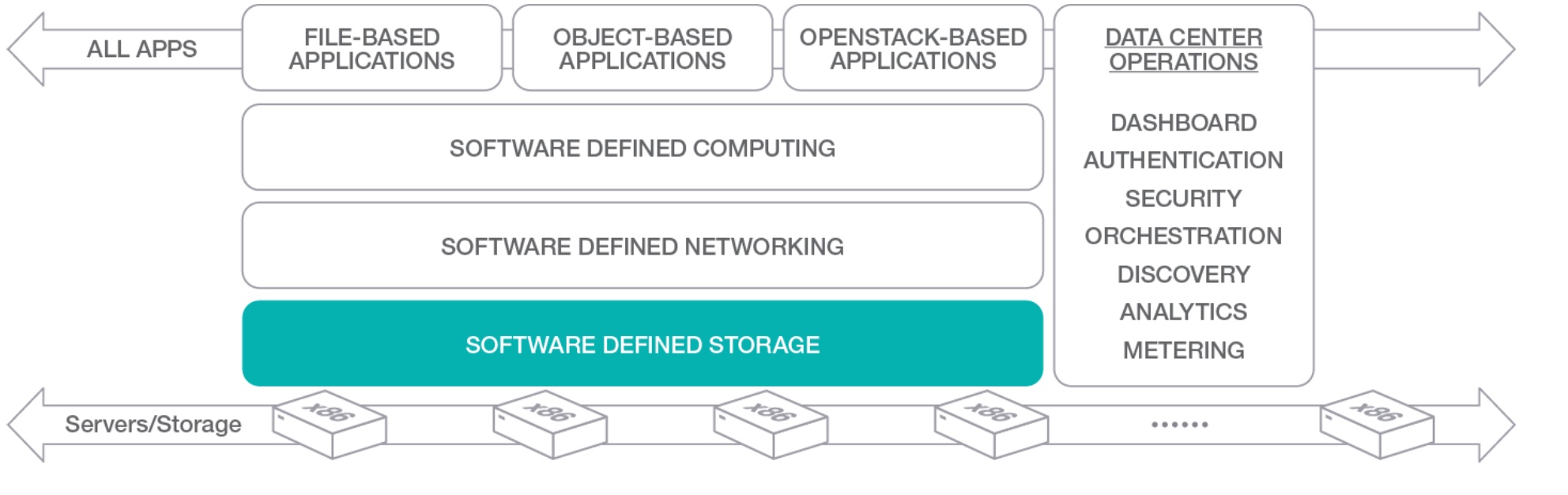
This aggregation is the key point for the availability: while traditional storage systems based on storage processor, degrading their performance by the growing of the capacity, this scale-out storage system, increases availability and performance because distribute data and workload across multiple x86 systems. This guarantee a great data and effort distribution, spanning the application requests across multiple nodes. The result a high capable, powerful and resilient storage at a lower cost.
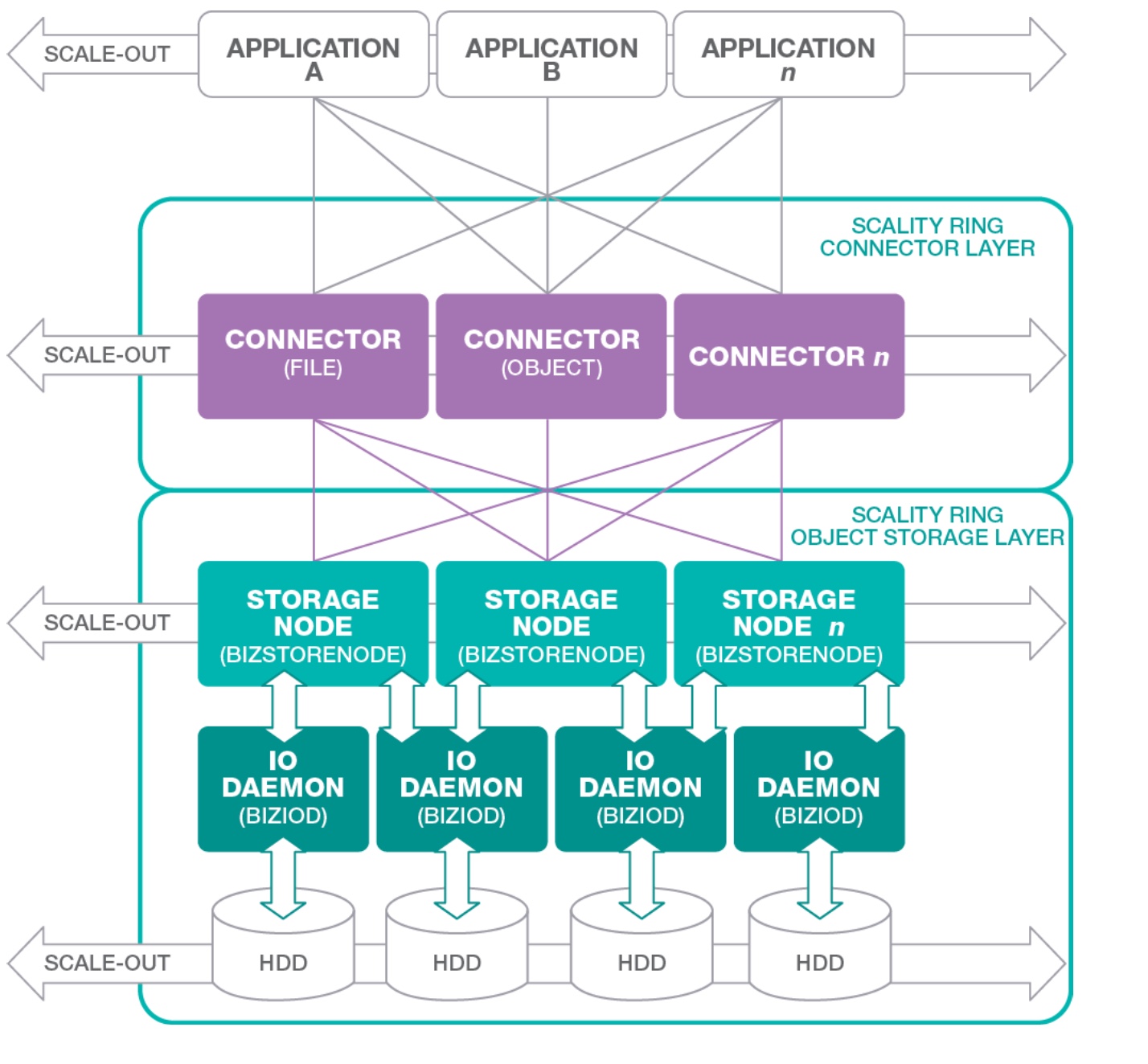
Talking about protocols, Scality exposes NFS, SMB, Linux FUSE interfaces and S3 REST API.
After Cloud Field Day, I was involved in a Scality use case…
The problem of storing data across in hybrid mode is the way that a startup located in Lugano, composed by developers without sysadmins, is trying to do to with an application that is producing multimedia contents. Low cost storage with scalability and availability without changing the way to access, is the challenge they are facing in this period and the integration with 3rd party software compatible with this kind of storage become also mission critical.
Scality S3Server, formally renamed in Cloud Server, is an open source project that acts as S3 endpoint for existing storage system: it provides an interface with 80% compatible with Amazon S3 API. In this way, without changing the “client” code, is possible to route traffic from inside storage to Amazon and vice-versa.
For further information check here:
- S3 API http://docs.aws.amazon.com/AmazonS3/latest/API/Welcome.html
- Cloud Server https://github.com/scality/S3
- Docker image for cloud server https://hub.docker.com/r/scality/s3server/
Zenko ( https://github.com/scality/Zenko ) is an open source project that come from Scality team, which provides an efficient data governance of unstructured data across private and public cloud storage: in few words is a Multi-Cloud Data Controller that expands Scality S3 Server. (source: http://www.scality.com/about-us/press/scality-zenko-multi-cloud-controller/)
Under the hood, Zenko is composed by NGINX, Scality S3 Server (aka Cloud Server), DMD (data and metadata daemon) and Redis.
Note: Other than the simple deploy using Docker, in the official docs, there is a procedure to deliver Zenko in production using Docker-Swarm (in HA).
Highlights During the Cloud Field Day
During the presentation Giorgio Regni, CTO at Scality, shows the recent goals in the Scality roadmap, where the boundaries with open source and community are one of the key points for future releases.
Bringing the focus on S3 Enterprise, Paul Speciale (VP of Product manager in Scality), illustrates the product release history and the collaboration with the open source elements around the product.
[vsw id=”HwW-rWoS4lI” source=”youtube” width=”425″ height=”344″ autoplay=”no”]
Another good point is the use case that fits with Scality: near Internet Of Things, the healthcare storing medical image at an affordable cost. The demo by Rahul Padigela (Technical Lead in Scality), was the best way to show the Scality Backbeat CRR (Cross Region Replica)
[vsw id=”Tz9XJgI9l_I” source=”youtube” width=”425″ height=”344″ autoplay=”no”]
With a nice citation of the famous Romeo and Giulietta (Shakespeare), Lauren Spiegel, technical lead of S3 in Scality, illustrates how to retrieve information with extended AWS S3 API in Zenko (The metadata search engine is based on Apache Spark).
[vsw id=”x031pw9U0RE” source=”youtube” width=”425″ height=”344″ autoplay=”no”]
My POV and Tryout
Near the use case, I put my hands on Zenko and Scality using the 3hrs trial available in the site. There is a comfortable way to test the key features of this product in guided way and in the same way, like VMware HandsOnLab, is possible to navigate and test the functionalities because the demo is a fully functional environment that is delivered at every “Free Trial” requests.
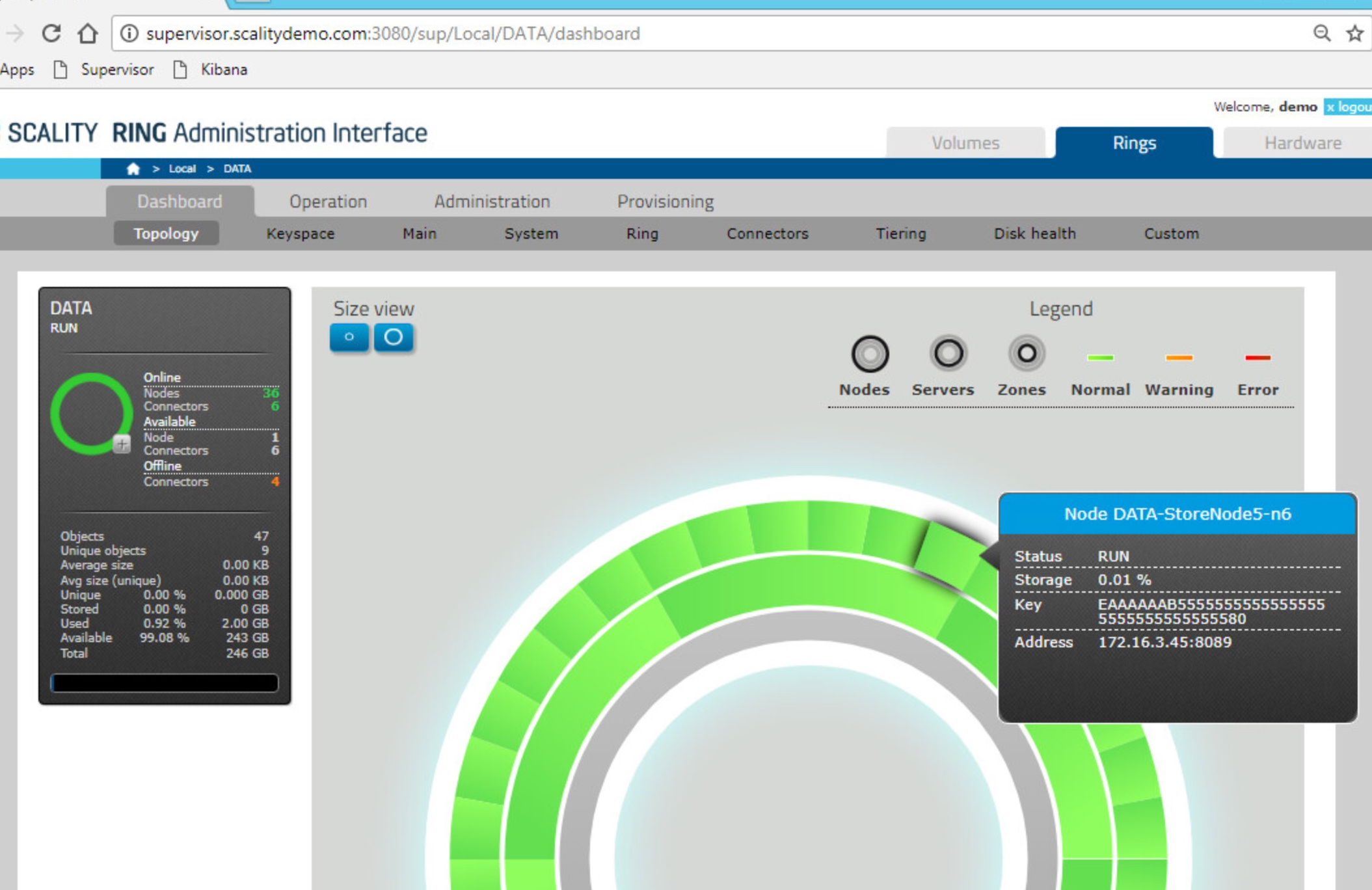
About Zenko, the tryout is really easy: if you have an amazon account and a PC running Docker, you can easily test all the stack with a simple command:
|
1 |
docker run -d --name s3server -p 8000:8000 scality/s3server |
This solution is an interesting way to develope and deploy applications that consume a huge amount of data and require a fast way to access regardless their location ( on-premise and in cloud ). For cloud providers, where the scaling is one of critical point their business plans, this could a solution that could fits on the on-demand requests and guarantee resiliency and capacity at linear cost.
Disclaimer: I have been invited to Cloud Field Day 2 by Gestalt IT who paid for travel, hotel, meals and transportation. I did not receive any compensation for this event and None obligate me to write any content for this blog or other publications. The contents of these blog posts represent my personal opinions about technologies presented during this event.